
Hi! This is hollowaytape, the hacker/developer for 46 OkuMen. Today marks three years since we formed this group. We’re hard at work on some non-technical parts of our current and future projects, so I thought I would take this chance to write a little series about my prouder moments from our first handful of translation hacks.
First, I will describe the process of random flailing, blind luck, and help from others that led to the key breakthroughs of our first few projects. Then, I’ll step through a few of the more impressive technical things I could accomplish once I had a firmer grounding in x86 assembly. Finally, I’ll talk about some of the absurd technical hurdles I’ve found in games we haven’t picked up as projects, which I haven’t been able to solve.
They aren’t tutorials or rigorous technical documents. Instead, I’m hoping just to give you a taste of what PC-98 romhacking is like, give some advice if you’re tackling a similar problem, and share some amusing and dumb things I thought along the way.
As the story goes, I volunteered to help out on the 46 Okunen Monogatari project on 9/25/2015. I had two years of hobbyist programming experience, but no real work with games or reverse engineering. I already knew Romhacking.net (RHDN) was the main resource to look at for romhacking tutorials, utilities, and generally helpful people, so I checked out their FAQs and beginner tutorial sections as a place to start. There was a lot of advice given in these guides that was superfluous or otherwise poorly-suited to Japanese PC romhacking, but where else was I going to start? Those guides hadn’t been written yet (and they still haven’t).
I knew I would need a hex editor, so I get the one that’s recommended in all the guides – WindHex32. I thought it was promising that it was listed for the “Windows” platform and not “DOS”, but the program is still from 2005, and it shows. I was immediately horrified by the tiny “browse” window I couldn’t resize, the idiosyncratic scrollbar, and the fact that my scroll wheel had no effect.
Either way, I opened up the main game disk and looked around. Mostly a bunch of incomprehensible garbage, but occasionally I’d come across something like this:
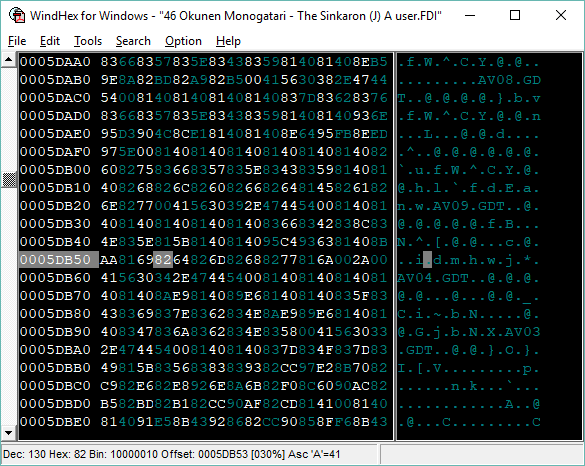
You can see some filenames in there – AV08.GDT, AV09.GDT, etc. Something recognizable among all the code. But where is all the text that shows up in-game? Let’s see if we can display this output any differently…
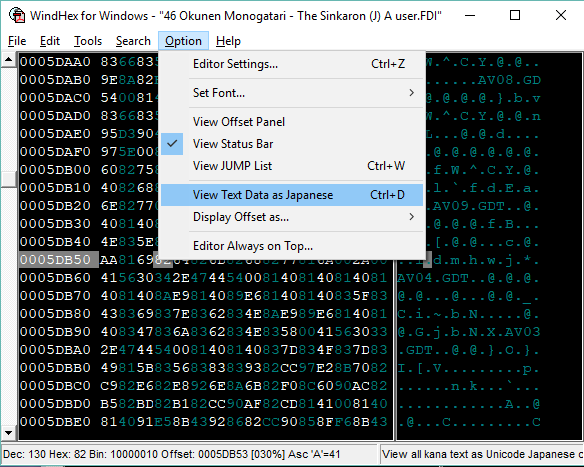
No dice. Back to consulting the guides. According to them, the first step to finding encoded text data was to try doing a “relative search.” In NES and SNES games, the font is stored as part of the graphics data. So, any reference to text will be internally represented as a series of numbers referring to the tile index of each letter in the graphics data. The alphabet can start at any point in the graphics data, so the text “ABC” might be tiles 90, 91, 92 or 187, 188, 189, but always hopefully in the same order as the alphabet, with no breaks in between letters.
The romhackers of old devised a tool in which you could input the text “ABC” and it’d search for the byte sequence (1, 2, 3), (2, 3, 4), … (n, n+1, n+2) in a file. Any three-byte sequence increasing in that exact way could possibly be the game’s way of representing “ABC”. The longer the sequence, the more confident you can be that the rest of the text is encoded in a similar way.
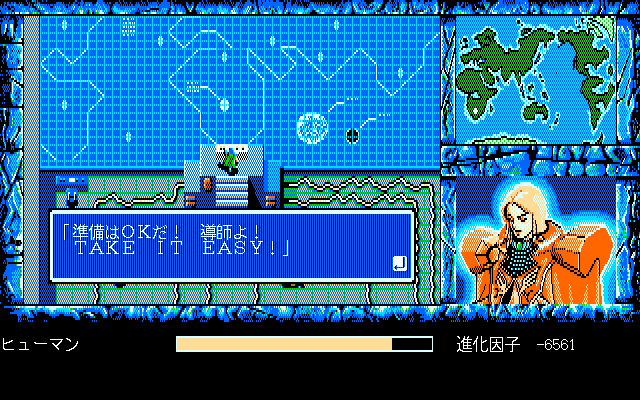
Also, this isn’t a great way to locate Japanese text immediately – you need an English string to look for with this method first. (I imagine you could do this with hiragana/katakana too, but they are apparently not in standard order a lot of the time.) I had recently finished the game, so I had some candidates in mind – the game begins with “ENIX PRESENTS”, but the more fun option is when an American character tells you to “TAKE IT EASY!” towards the end.
If you want more details on relative searching and its applications in console romhacking, check out the loftily-named “The Theory of Relative Searching.” It’s full of pictures and it even has exercises!
I downloaded Monkey-Moore, a highly recommended relative searching tool, and tried it out.
No luck yet. But after staring back at WindHex and those AV*.GDT filenames for a while, I noticed how that 81-40 sequence seemed to keep repeating. Elsewhere, I noticed byte sequences like:
83 4f 83 7d 83 49 81 5b 83 56
They look like pairs, where the first is always 80-something and the second varies a lot, between the values of 40 and 80. What if I’m looking for a scheme where every second byte defines a letter, and between them are values like 83, which have some other meaning?
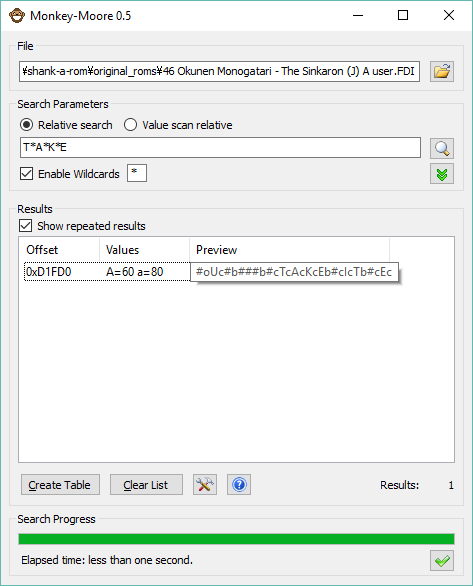
That’s funny… A=60 and a=80 in (decimal) ASCII as well! From this we can conclude that the English text is represented internally as ASCII, but with a lowercase “c” prepended to each letter.
Of course, that’s not really what’s going on. I did some research into Japanese text encodings and learned about Shift-JIS (SJIS). It includes ASCII as a subset, but it also contains fullwidth text, which I knew better as “vaporwave text.” Each character is twice as wide as an ASCII character, and takes two bytes instead of one. In SJIS, you can convert an ASCII character to fullwidth by putting an 0x81 byte in front of it. One distinction I forgot to make was that the American doesn’t say “TAKE IT EASY!”, he says "TAKE IT EASY!"
One advantage of WindHex mentioned in these tutorials was its support for .tbl files, which let you assign particular meanings to sequences of bytes:
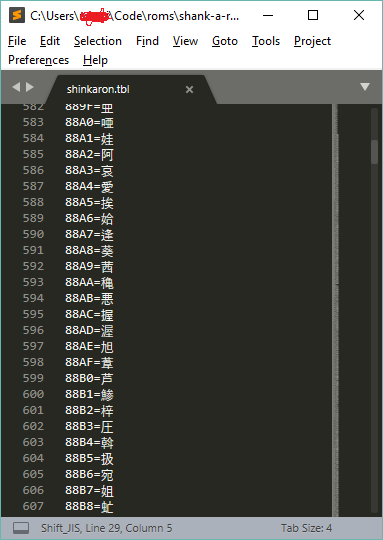
You can plug this into WindHex, which would display the bytes on the left, and the .tbl interpretation on the right. Luckily, there was a ready-made sjis.tbl file I could find on RHDN, so I could plug that in to WindHex and see text immediately.
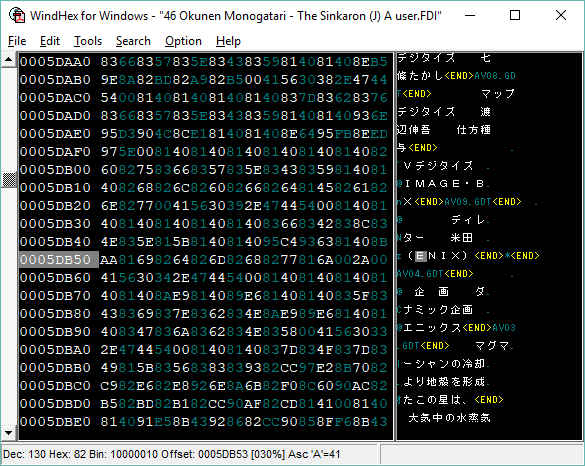
There we go! That’s some credits text from the opening sequence, so those filenames are the images that are cycled through as each string is displayed. Once I knew the encoding, I could write some tools to extract the text and dump it into an Excel spreadsheet, where translation could begin.
Since then, I’ve learned that basically every PC-98 game uses SJIS*, and for good reason. The PC-98 internal font is stored in a way that’s really easy to access and print characters if they’re stored in SJIS. (More on that in a later article.) Because of this, I have never needed to repeat this process.
*I know of four exceptions so far: Different Realm uses a proprietary Glodia text-encoding method based on regular old JIS (non-Shift, that is). Wind’s Seed, Libros de Chilim Balam, and Tamashii no Mon each use SJIS, but replace the ASCII with kana/numbers for better compression. Those last three were figured out by celcion, kuoushi, and danke respectively.
I’ve also since then switched to a much more modern hex editor called wxMEdit, which can display text in SJIS at the touch of a button:
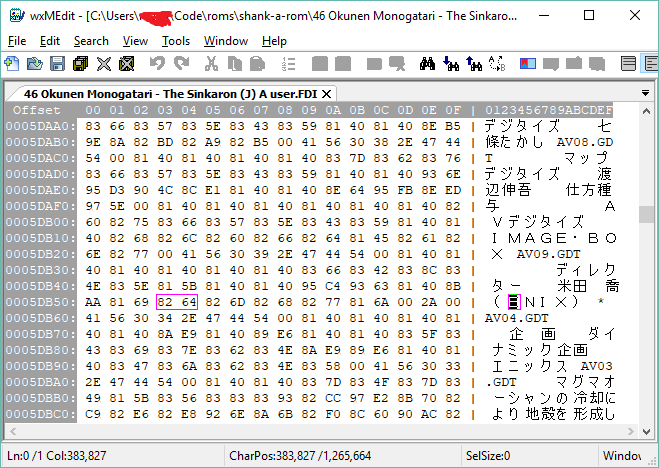
So useful! It is not listed in the RHDN utilities section of course, nor is its very popular predecessor MadEdit, since old console games usually don’t use SJIS or other standard encodings. But for me, and anyone else poking around at old PC games of any kind, this tool is a great choice.
Next time: reverse-engineering E.V.O.’s proprietary .GDT image format.
Nice, but when you figure out where the text and graphics are, how can you make a tool to ease the process of extracting and packing new graphics into the game? Can you share some information about that?
Also, are there any other projects you are considering working on at the moment? Would it be possible for you to look into a game called RELICS? It doesn’t have much text to translate (In fact, most of the game is already in English, except for the ending text and warning/story in the beginning)
Of course, I don’t mean to push you or demand anything, just my 2 cents.
Check out part 2, which I just posted – it’s all about a graphics encoder for E.V.O. I’ll be covering a few different graphics encoders I needed to write in this series, since it’s often the hardest thing I need to do for each project.
Our hands are pretty full these days with Appareden, Different Realm, and some things we’ve not announced yet. We also keep a list of games we’re interested in tackling later here: https://46okumen.com/projects/project-candidates-page/
> That’s funny… A=0x60 and a=0x80 in ASCII as well!
> From this we can conclude that the English text is
> represented internally as ASCII, but with the lowercase
> “b” (0x81) stuck between each letter.
Er, a lowercase ‘b’ is 0x62.
You’re shoving decimal numbers into hex notation without actually translating it to hex…
Also, it pains me that you’re opening the whole floppy disk image in a hex editor instead of extracting the files within with e.g. anxdiet. Those things (usually!) hold a regular DOS file system inside with disparate files. At least for newer games.
You’re right, I did confuse my notation there. I’ve fixed it now.
Sorry for the pain I’ve caused you! I am quite aware of the discrete files in each disk, and usually recommend DiskExplorer or ND.exe to extract the files if you’re going to be editing them. But if I’m just giving the game a cursory look to see if there’s plaintext /anywhere/ in it, I would want to look at the whole disk in a hex editor, just so I could run searches on the whole game, rather than need to run searches through each individual file.