
When a game’s developer writes code, they usually* do it in a reasonably high-level language like C++. They have access to all sorts of nice things like variable names, function labels, comments, and so forth. When it comes time to run the code, it is compiled through something like Borland Turbo C++, and it is translated into assembly language (ASM) for the target platform, in this case the PC-98’s x86 processor. The compilation process strips away all of the useful names of things, determines exactly how all of the data needs to move between registers and memory, and does what it can to optimize the program. This much more difficult-to-understand code is what remains in the final .EXE that ships on the game disk. Since we don’t have the source code, we need to look to the ASM in order to understand and modify the game.
I had a lot of unsuccessful interactions with assembly language, across several projects, before I was finally able to successfully modify it, which I needed to for Rusty.
Struggling Blindly Without ASM
First, I was missing a key insight about the text pointers in E.V.O., without which the translation would have been impossible. joseji from the Heroes of Legend forums was kind enough to figure this out for me, and pointed to a screenshot of some of the game’s ASM as evidence.
It turned out the pointers weren’t neatly lined up in tables (as is typical of console games), but hard-coded and spread throughout the code segment of the file. I never would have found this if no one had pulled out the debugger and taken a look.
Next, I was looking at Rusty in np2debug to see what kind of code was executing when text was displayed in the first cut scene. With np2debug, you can tell it to pause execution at a breakpoint. For example, when it reads a character, we can see which ASM instruction is doing the reading, and everything after that. I did this, and wrote down a lot of the instructions that were happening, but I didn’t know what I was doing at all. I just have pages and pages of instructions, and have no idea which ones are the important ones.
Finally, I had modified some ASM for a new project Appareden in the dumbest way possible. The game uses the bytes for “n”, “c”, and “w” as control codes, which means we couldn’t use those letters in the script if I couldn’t reassign those control codes to something else. So, my solution was to locate all the values of 6e in the file, and replace different subsets of them until I could get an “n” to display properly. There were 286 n’s in the file, and as it turns out, the 104-107th and 109-110th n’s need to be replaced. I did this for “c” and “w” as well. That’s a lot of trial and error.
The lesson is, you can accomplish some of these things without having any comprehension of what’s going on at the instruction level, it just really sucks.
*Different Realm was written directly in ASM. When ASM is directly hand-written, it at last has variable names and macros to encapsulate the more repetitive tasks, so it isn’t quite as arcane as you’d think. But it gives great control over the program’s performance, which probably explains why Realm runs so well and scrolls so smoothly.
Rusty’s Text Problem
So, it was a long-standing problem in Rusty that it wouldn’t accept any ASCII text in any of its myriad menus. Fullwidth text would display fine, but that leaves you very little room to write anything worth reading. When you put ASCII in, it would output tons of garbage:

Occasionally, within all of the garbage, there would be some halfwidth Latin characters (see J, N, r, 9, k…), but never the ones you wanted. So the game was definitely capable of displaying them somehow.
I was under the impression for a while that the game was using its own font file to write these characters, since they were larger than normal, with shadows and colors. Supporting this theory was a very tempting filename I found on the disk – “FONT.DAT.” But I looked in this with a tile editor and discovered it was just a font for the gameplay UI and the sound test:
Not really what we’re looking for. I finally put the custom-font notion to rest by changing the system font in the emulator options, which changed the displayed character appearance as well:

The game was indeed using generic system functions to get characters from the internal system font. It just did so in a way that would only allow two-byte characters to be displayed. This called for a more carefully-considered solution.
Step 1: Displaying Different Characters
First of all, I stopped trying to read the ASM from the first cut scene. Cut scenes are fairly complicated – they’ve got music, mouth animations, colors and text blips, etc. It’d be much simpler to look at the pre/post-boss dialogue, which takes place against a static background, and usually has no music, with comparatively very plain text. So, the instructions being executed in that scenario would much more likely be relevant to displaying text.
I replaced a bunch of text in the Level 1 post-boss scene with a nice, predictable fullwidth ABC. I set breakpoints at every byte of this text, so I could see what was happening when they were read.
The answer was, of course, a lot. Let’s take the example of A, or 82 60. The bytes would be read into the AX register, then a bunch of math would be done to it, and it would be transformed into 41 03. Then some stuff would happen to it and it’d be discarded.
I watched this process happen to a few different characters:
A : 82 60 -> 41 03
B: 82 61 -> 42 03
C: 82 62 -> 43 03
a: 82 40 -> 61 03
b: 82 41 -> 62 03
c: 82 42 -> 63 03
た: 82 bd -> 3f 04
ち: 82 bf -> 41 04
つ: 82 c0 -> 44 04
タ: 83 5a -> 3f 05
チ: 83 5c -> 41 05
ツ: 83 5f -> 44 05
There’s a pattern starting to emerge here, but it’ll become clearer with an additional element.
What was the last point at which this new value was used before being discarded? it looked like it was this series of instructions:
out a1, al ; send AL to I/O device A1
mov al, ah ; AL = AH
out a3, al ; send AL to I/O device A3
The two halves, 41 and 03, were being sent to the I/O devices labeled a1 and a3. According to this crucial document that’s now offline, those correspond to the “Character ROM.” That sounds useful.
If you’ve set up a PC-98 emulator, you know you need to supply it with a BIOS file called FONT.ROM. One that’s commonly available is called anex86.bmp, which you can open up in Paint and see it’s just a huge grid of all the characters.
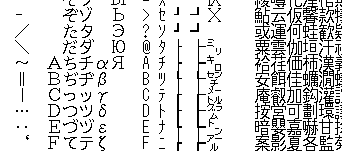
Notice the columns in the order: fullwidth Latin, hiragana, katakana. The fullwidth Latin characters were given the second byte 03, the hiragana 04, and the katakana 05. And you can see that A, ち, and チ are all in the same row, and share the same first byte 41.
From this, we can conclude that if you’re trying to get a character from the Character ROM, you send the row number to a1 and the column number to a3.
So the key is to feed different numbers to the Character ROM. To get fullwidth ABC to display as halfwidth ABC, we need to access column 08 instead of 03.
One of the last math instructions that produces the number is this:
sub ax, 2000
Changing that to sub ax, 1b00 produces a result with a column byte 5 higher than before, or 08, which finally renders some predictable halfwidth text.
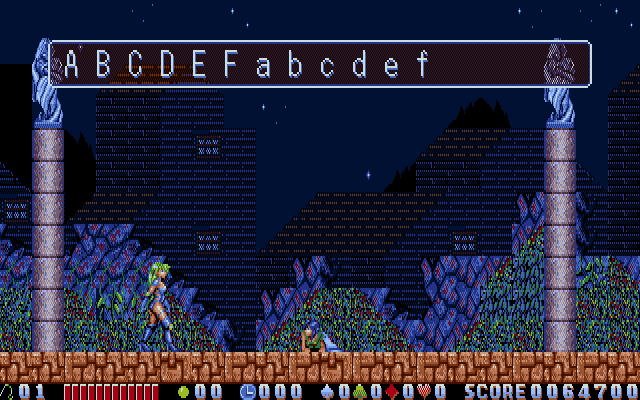
Looks pretty great so far! But the text in the file is still fullwidth. There’s not enough space in VISUAL.COM to fit the whole script as fullwidth characters, so some more work is needed.
Step 2: Reading Every Character
Back to setting breakpoints at each byte and seeing what happens. Here’s a segment that deals with how the first and second byte are loaded separately:
lodsb ; read first byte
mov cs:[409d], al ; store it somewhere
...
lodsb ; read second byte
...
mov ah, cs:[409d] ; put that stored first byte in AH
lodsb is a very useful instruction to know for text hacks. It loads the byte at DS:SI into AL, and automatically increments SI.
When the first byte gets loaded into AL, it is immediately written to a location in memory, where it can be fetched into AH later, and the math can be performed.
In that case, I can erase the part where it loads the first byte entirely, and just have it load a plain 82 instead when the time comes to put something in AH:
nop ; replace the old instructions with a "do nothing" instruction
nop
nop
lodsb
...
mov ah, 82
Since it’s only calling lodsb (and therefore incrementing SI) once per loop, it’s not reading every character. Here’s the result:
Step 1 of this hack was to have it read fullwidth text and display halfwidth text. With Step 2, it reads halfwidth text, tacks on an 82 to make it fullwidth, then displays it as halfwidth anyway. It’s a little roundabout, but it gets what we want.
Step 3: Cursor Fix
Now, the final touch is to squish the characters together. Otherwise it’s really no better than fullwidth text in terms of screen space and readability.
This was not quite as difficult. I set a breakpoint at each character, and dumped the memory after each one was displayed. I used VBinDiff (which shows you the byte-level differences in two files) to look at all the values that increased each time. I found a few candidates and edited them in memory to see which one would make the game start printing characters in weird places on the screen. I set some breakpoints to see what was happening to that value, and found this:
add di, +04
mov cs:[somewhere], di
Changed the 04 to an 02, and all the text squished together beautifully as intended.
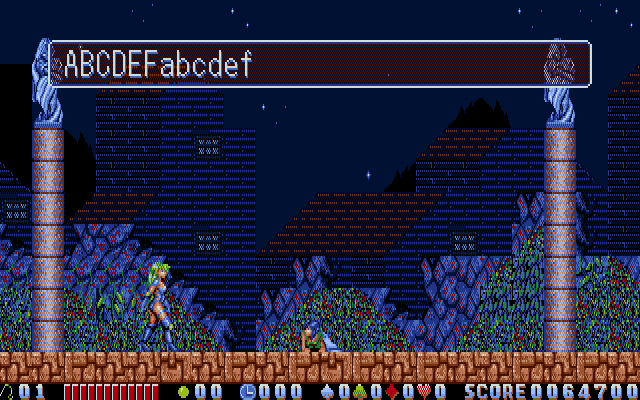
And that’s all we need to start inserting the translated script into Rusty.
After getting plenty of practice doing this text display hack just for Rusty, which needed it done four times (boss/girl dialogue, cut scenes, menu, game over), I’ve done basically the same hack in several more recent projects, with the same 3-step process. Getting comfortable with ASM hacking in general led to a lot more flexibility in the next few translations, letting me do things like change text speed, get around string length limits in CRW, add text compression to Appareden, cheat my way through some games that were too hard, and lots of other fun stuff.
Adding halfwidth text support is crucial for getting a readable script into the game. I’ve seen some aspiring PC-98 translators find a cool game they want to translate, but their enthusiasm quickly drains away when they discover this obstacle and that they’ll need to hack it to get anything done.
So, my next post will be a more explicit tutorial on how to use np2debug to accomplish this. Hopefully that can help the next person pass this obstacle.
I recently found this site and started reading through your blog.
I find quite impressive what you have figured out and just wanted to say keep it up and thanks for sharing your journey.
try radare2 tools, it’s hard at first but later it is irreplaceable for hacking x86 asm
when last time i tried radare2 (probably early 2019), its lack of proper handling/showing segmented memory made it almost useless for reversing any real-mode 16-bit x86 programs, potentially including most, if not all, retro pc-98/dosv games. did you have any solution/workaround for such problems?
So, what’s the formula for translating between SJIS and the “character ROM” representation?
In other words, how do you make 82 bd into 3f 04?
Also, what is that “other font” in https://46okumen.com/wp-content/uploads/2018/11/rusty_sysfonts-1.gif ? I wasn’t aware that there were many fontsets floating around.
Yeah, I left this out and just said “a bunch of math.” Here are the details. If EAX is 82bd (た), it’s this set of instructions:
add ah, ah ; 82 + 82 = 104. EAX = 04bd
sub al, 1f ; 9b - 1f = 7c. EAX = 049e
add ax, 1fa1 ; 049e + 1fa1 = 243f. EAX = 243f
and ax, 7f7f ; it's still 243f EAX = 243f
sub ax, 2000 ; 243f - 2000 = 043f EAX = 043f
So I think the formula would be:
y = ((x + ((x // 0x100) << 8) + 0x1f82) && 0x7f7f) - 0x2000.Depending on how robust of an answer you want, I think there is an additional step at the beginning where you adc 0xde to al if al < 61. I am only aware of two fontsets - there's anex86.bmp, a font that comes with the Anex86 emulator that has very spindly and ugly Latin characters, and font.bmp, which is something ripped straight from someone's PC-9821 hardware.