
While we were finishing up the E.V.O. translation, we weren’t sure whether we wanted to work on more translations together. Our group didn’t even have a name yet. But we were starting to test the waters a little bit. Kuoushi was looking at Libros de Chilam Balam, and I was hearing about some other games in the PC-98 Discord server. I came across a tweet from another PC-98 romhacker, Nana, who had this to say about Rusty:
Rusty is the primary reason this little collage got out two days later than I had intended, haha. Game's code is a nightmare.
— Nana (@Nana_VS_Nana) September 1, 2016
I had at least heard of the game before from its HG101 article, and for some reason I wanted a challenge.
Rusty was kind of a weird project in retrospect – it’s in a genre we usually ignore (hard action platformer), it looks an awful lot like it’d be a hentai game (which we just claimed we wouldn’t work on), and it doesn’t even have that much text. But it was where I started to develop some proper romhacking skills, like assembly modification and handling data compression
There are quite a few types of text present in Rusty:
-
- Opening text, in black-and-white images
- Main menu and game over interface text
- Cut scene text
- Windowed text before/after boss fights
- Text in the post-boss “girl you rescued” images
- Ending plot text
Ending credits text in images(already English)In-level interface text(already English)
They’re all displayed differently, so each one would need its own hacks to get working. I started with the cut scene text, just because it seemed the most important, and I didn’t have to play any of the game in order to get to it. (As I mentioned, the game’s hard.) Simply being able to extract this text in a usable form will make up the entirety of this post.
The first cut scene begins with this line:
Since I knew it would probably be Shift-JIS, I could look around in some files for that initial “この”. I could look for it in its hex form (82 b1 82 cc), but with wxMEdit you can just look for the string itself in all the files of a directory:
There, not too bad. Now, let’s take a look in VISUAL.COM…
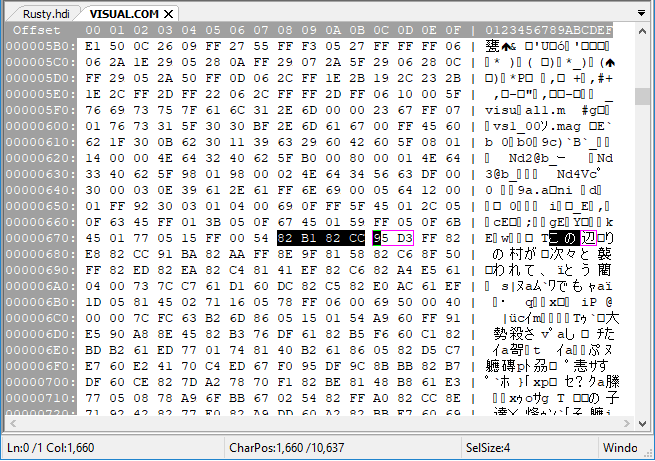 The first line begins “この辺りの村が次々と襲われと、とうとう”. The first part (この辺) emerged unscathed, but beyond that, things are a little different. The string gets split up by these
The first line begins “この辺りの村が次々と襲われと、とうとう”. The first part (この辺) emerged unscathed, but beyond that, things are a little different. The string gets split up by these FF characters, the first of which appears before the beginning of the string, and reoccurs every few characters like this:
FF__ この辺
FFりの村が
FF次々と襲
FFわれと、
It shows up before every group of four characters, that is, eight bytes. But right after this, it gets a little less straightforward.
EFとうe5 61 04 00 73 …
What’s going on here? Looking ahead in the file, there are a handful of characters recognizable as being from that first line, but they appear less and less often, surrounded by more and more garbage. This seems like a pretty good indication that Nana was right – there’s some compression going on here.
One important thing we can note immediately: the plaintext is “とうとう”, and とう only appeared once in the compressed text. Any good way of compressing text would have a way to repeat some text that has appeared before. Somewhere in the next few bytes, e5 61 04 00 73 ..., there’s likely to be a way to access that previous とう. But which bytes, and how do they signify that?
We’re not starting from nowhere, fortunately. In a lucky break, there’s a telltale signature in the file’s header. I’d gotten used to the .EXE files in E.V.O. beginning with the signature MZ, the EXE inventor’s initials. But this file, along with all the other files I was interested in, began with LZ:
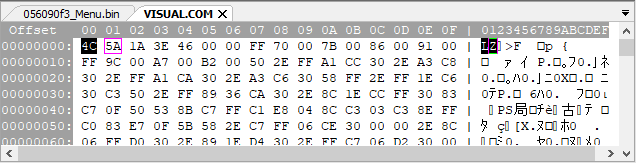
I knew that “LZ” is a large family of common compression methods, including LZW, LZSS, and LZ77. They’re all variants on dictionary compression, where the compressed data is made up of plain data, pointers to previous data, and flags to tell you which is which. LZSS in particular had shown up in a lot of romhacking documents, since it was used in some famous Squaresoft games in the SNES/PSX era. I figured it was a good place as any to start looking.
A resource I ended up using to learn about LZSS was an entry on a rather inactive PC game file format wiki called XeNTaX. I recommend reading that if you want some more details.
LZSS keeps a buffer where all the plaintext is written during decompression. Since とうとう is represented once as plaintext and once as a pointer to the same plaintext, the buffer would still contain とうとう. Pointers in LZSS work by pointing to a particular location in this buffer, and specifying a number of bytes to copy. To distinguish between pointers and literals, there’s a one-byte flag, which declares the next eight things as literals (1) or pointers (0). That’s why there were so many FF (1111 1111)s before – they announced the eight literal bytes to follow.
The EF flag has the bits (1110 1111), and that segment had four literals (the bytes for とう), then some stuff we don’t know. So, the bits should be read from right to left – the flag signifies 4 literals, a pointer, and 3 more literals.
LZSS pointers are two bytes long, so the pointer that points to that とう is e5 61. Is there anything in those two bytes that seems to mean “look 4 bytes ago, and copy 4 bytes”? Not particularly. We’re going to need more data.
With np2debug, the full decompressed file can be dumped from memory. I can compare the compressed and decompressed versions, noting where in the decompressed version a pointer appears to point, like this:
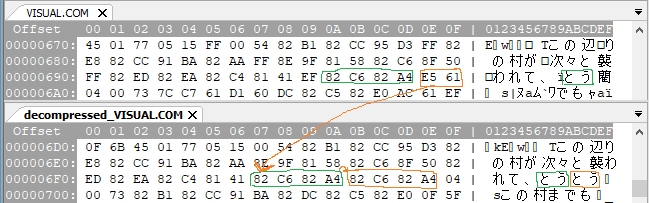
e5 61 points to the location 6f7 and copies 4 bytes.I did this for a bunch of pointers, starting at the beginning of the file:
00 00points to12, copies 3 bytes
07 00points to19, copies 3 bytes
34 00points to46, copies 3 bytes
38 00points to4a, copies 3 bytes
44 01points to56, copies 4 bytes
4c 15points to15e, copies 8 bytes
With that many examples, we can start to see a pattern. The first four pointers all copy 3 bytes, and have a final nybble as 0. When that nybble increases to 1, it copies 4; when it increases to 5, it copies 8. So, the length is the final nybble + 3. (Why + 3? Because a pointer itself is 2 bytes long, so it isn’t efficient to copy anything less than 3 bytes.)
As for the location, this also increases with the remaining 3 bytes of the pointer. With the lowest possible value 00 00 pointing to 12, adding 7 to the first byte to get 07 00 points to 19, which is 7 higher. This holds for all the other values. For three-digit hex numbers, the highest digit is the first nybble of the second byte: 4c 15 -> 14c. (When a number’s higher-place values are stored later in memory, that’s a characteristic of a little-endian system. It’s common in the PC-98 and all sorts of other computers and consoles.) Add 12 to that value and you get the pointed location. As for why 12? I’m not totally sure.
To sum it up: For a pointer WX YZ, copy Z + 3 bytes from the location YWX + 12.
A few more quirks:
VISUAL.COM is 4630 bytes long, but these pointers can only point to a three-digit location, fff at most. No worries – the buffer is circular. For example, there’s a pointer 59 02 which points to some bytes at 106b. The location part of the buffer says it points to 06b. So, once the buffer goes past the fff limit, it begins writing from the beginning again.
At 38b in this file, there’s a pointer e2 f9. It should apparently point to ff4. But ff4 is pretty far in the future, so there’s no data there yet. What gets copied? Twelve bytes of 00. So, that tells us how the buffer is initialized – the whole buffer is 00‘s until stuff is written to it.
That’s enough to write a LZSS decoder for Rusty. Mine can be found as the decode() method here. Other games, even if they use LZSS, might have different parameters – different buffer sizes, pointer formats, location constants, etc. But the principles are the same.
Like with the .GDT encoder, writing a script to re-compress these files after edits is a lot simpler than writing one to decompress them. We can ignore all the pointer nonsense entirely and just write literals, with the FF all-literal flag every 8 bytes. It’s really just this:
write "LZ"
while there are still bytes:
write FF
write 8 bytes of the file
That’s it. Just because you’re writing an LZSS file doesn’t mean you actually need to make use of the compression. Since there was plenty of space in the Rusty disks, this was a temporary solution that never really needed any further work. All the edited files in our final translated version are “compressed” in this way.
Thanks for reading! Next time we’ll modify the game’s code to allow English text to display in the pre-boss cut scenes.
Did VISUAL.COM contain more than just text? It seems foolish to me to use compression for such small amounts of text.
The compressed VISUAL.COM was 4630 bytes, but how much was it uncompressed? What sort of compression ratio are we talking here?
VISUAL.COM is like 1/4 text and 3/4 code. But the same compression is also applied to pretty much every other file in the game, including stuff like images.
Compressed, VISUAL.COM is 10,367 bytes (0x298d), and decompressed it’s 17,381 bytes (0x463d). So the file is about 58% of its original size after compression. Seems pretty good to me. The rate is roughly the same for a few images (.MAGs) I checked.
A Japanese person known as UME-3 did a CLI tool for extract LZ-compressed files for C-Lab games. The purpose of the tool is to decompress the music files to make a package for a sound hardware emulator called hoot, but it can be used for all LZ-compressed files. And it includes source.